What is Snowpark for Python, actually?
In June 2022, Snowflake announced the public release of Snowpark for Python. But it's hard to tell what it actually is. It turns out to be a confusing collection of libraries, features, and other stuff.
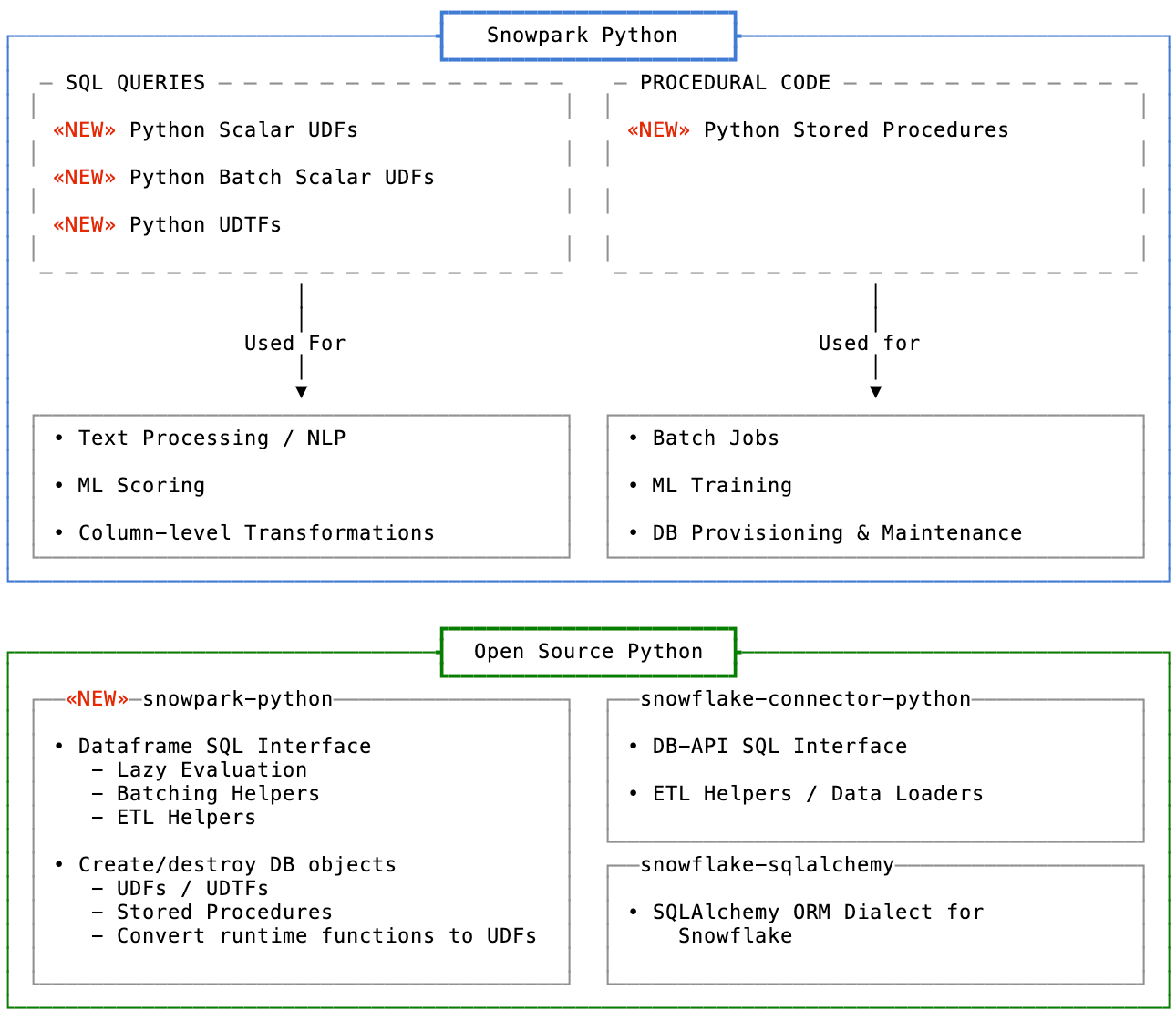
Snowpark for Python is made up of:
- A Python execution engine hosted on Snowflake's compute infrastructure
- Python language support for UDFs (user-defined functions)
- A new hybrid UDF type - Batch UDFs
- Python language support for Stored Procedures
- A new open source library named snowpark-python
Let's look at each.
The Python execution engine
This seems straightforward - a Snowflake virtual warehouse (their term for a compute cluster) can now run Python code. This lets you process data in Python without leaving the database. No need to extract or load, you just run Python.
Your Python code can now sit closer to your SQL transformations. This means it's a bit easier to compose the two into a single data pipeline.
But it's more complicated then it looks - there's actually two separate execution engines:
- The UDF engine. This is a restricted Python engine that cannot read or write data out of Snowflake.
- The Stored Procedure engine. This is a more permissive Python engine that includes the
snowpark-pythonlibrary and aSessionobject for interacting with the database.
Python language support for UDFs
Snowflake supports user-defined functions, a feature that allows developers to write their own re-usable functions. Python joins the existing lineup of languages supported for UDFs - Java, Javascript, and SQL.
Snowflake has a few different UDF flavors, Python is now supported for all of them:
- Scalar UDFs. These functions are invoked once per row. You call them like you would any normal SQL function - you pass in columns or SQL expressions as arguments and you get a single value out.
//
// Python User-Defined Function (Scalar UDF)
//
create or replace function plus_one(input INT)
returns INT
language python
runtime_version=3.8
handler='plus_one_handler'
as $$
def plus_one_handler(input: int) -> int:
return input + 1
$$;
SELECT plus_one(1); // -> 2- Tabular UDFs / user-defined table functions (UDTFs). These functions are invoked once per row like scalar UDFs, but they can maintain memory between invocations. UDTFs return multiple rows as output and are used in the place of a subquery, a CTE, or a temporary table.
//
// Python User-Defined Table Function (UDTF)
//
create or replace function explode(data VARCHAR)
returns table (item VARCHAR)
language python
runtime_version=3.8
handler='ExplodeHandler'
as $$
class ExplodeHandler:
def __init__(self):
pass
def process(self, data):
for item in data.split('|'):
yield (item, )
def end_partition(self):
pass
$$;
WITH basket AS (
SELECT 'apple|banana' AS fruits
UNION SELECT 'pear|peach|plum'
)
SELECT item
FROM basket, LATERAL explode(fruits);
// +--------+
// | ITEM |
// |--------|
// | pear |
// | peach |
// | plum |
// | apple |
// | banana |
// +--------+
Python UDFs also feature a new capability that UDFs in other languages don't have - importing static files. At function creation time, you can specify "imports", arbitrary files stored on a Snowflake stage. These files can be anything, like Python code or raw data.
A new hybrid UDF type - Batch UDFs
Python support is bundled with a new flavor of UDF: batch functions. They operate the same way as scalar UDFs, but Snowflake will collect batches of rows and send them to your Python function as a pandas dataframe.
A batch UDF can take advantage of vectorized dataframe functions in pandas and numpy, significantly improving performance over one-invocation-per-row. You can tune the maximum batch size to ensure you don't run out of memory.
Any scalar UDF can be converted to batch with just a Python function decorator. I'm not crazy about this approach - I wish it was explicitly defined - but I can't complain too much because batch UDFs seem useful.
//
// Python User-Defined Function (Batch UDF)
//
create or replace function plus_one_batch(input INT)
returns INT
language python
runtime_version=3.8
packages = ('pandas')
handler='plus_one_handler'
as $$
import pandas as pd
from _snowflake import vectorized
@vectorized(input=pd.DataFrame)
def plus_one_handler(df: pd.DataFrame) -> pd.DataFrame:
return df[0] + 1
$$;
SELECT plus_one_batch(1); // -> 2Python language support for Stored Procedures
Unlike declarative SQL queries, stored procedures work more like what people consider "normal" programming - you write a series of code statements and they run in order. Python stored procedures are just a block of code you parameterize and then execute on demand. You can think of them effectively like an AWS lambda function.
Python stored procedures run in a less-restricted environment than UDFs. Each stored procedure automatically includes a database connection that can be used to execute arbitrary SQL, like creating/dropping objects or running queries for data. That makes them useful for data pipelines or database maintenance tasks.
//
// Python Stored Procedure
//
create table dirty_data
( fruit VARCHAR )
AS
SELECT 'apple'
UNION SELECT 'banana'
UNION SELECT 'ẑ̸̠ā̸͔l̴̛̙g̶̼͛o̵̬͗'
;
create or replace procedure clean_table(table_name STRING)
returns int
language python
runtime_version = '3.8'
packages = ('snowflake-snowpark-python')
handler = 'clean_table_handler'
AS
$$
import snowflake.snowpark
def clean_table_handler(session: snowflake.snowpark.session.Session,
table_name: str) -> int:
table = session.table(table_name)
result = table.delete(~table['fruit'].rlike('[a-z]+'))
# equivalent to `DELETE FROM dirty_data WHERE fruit NOT RLIKE '[a-z]+';`
return result.rows_deleted
$$;
CALL clean_table('dirty_data'); // -> 1
SELECT * FROM dirty_data;
// +--------+
// | FRUIT |
// |--------|
// | apple |
// | banana |
// +--------+The snowpark-python library
This is a Python library for Snowflake that has many new features, including:
- A dataframe SQL interface. This is similar to dbplyr, the "database backend" for the popular R library dplyr. It gives you a lazily-evaluated dataframe for composing SQL queries. This interface may feel more natural to those with lots of experience manipulating dataframes but don't feel comfortable writing SQL. It also makes it easy to move data between Snowflake and dataframes without the overhead of writing ETL code.
- Create DB objects from Python. This is like an ORM but it only supports a handful of objects (like UDFs, stored procedures, and tables) and only supports
create&drop. One neat feature I discovered is that you can pick functions in Python memory at runtime and upload the bytecode for them as UDFs to run in Snowflake.
This library has two key uses: in stored procedures and in data pipelines.
Python stored procedures automatically load snowpark-python and instantiate a working session for querying Snowflake. That's useful if you want to port a Python transformation to run on Snowflake infrastructure or want to use a sane programming language (sorry Jinja).
Outside of Snowflake, the library may be useful in data pipelines. It offers a new way to compose analytical queries that's more flexible than just raw SQL. In exchange, you add in a layer of abstraction that may or may not help you write more maintainable code.
Parting Thoughts
There's loads of cool libraries out there to help with routine data work. If you have text data from an unknown origin, you could use charset-normalizer to detect an appropriate encoding. Or maybe you need the advanced geospatial indexes provided by rtree. Python's vast open source ecosystem of libraries help enable some promising new use cases inside of Snowflake. There's also the moonshot possibility that teams start training machine learning models directly on Snowflake compute.
Let's see what folks come up with.